

Paratext has been designed with the ability to work with most of the world’s writing systems. For this purpose, Paratext has various language settings including the Alphabetic Characters dialogue. See the example for English below:

Lower and Upper Case Letters
The Alphabetic Characters dialogue (Project menu > Project settings > Language settings > Alphabetic Characters tab) is where all of the lower and upper case letters of a language are to be listed. This list tells Paratext which letters are part of a language and forms the basis for the Character check in Paratext.
💡 Note: Additional characters such as punctuation and numbers have to be added to the character check inventory manually (see Project menu > Tools > Checking inventories > Characters inventory OR Punctuation inventory), but everything in the Alphabetic Characters dialogue are added to the inventory as valid characters automatically.
💡 Note: The Alphabetic Characters list should only include characters or letters used in your particular writing system, so that the Character check can flag inappropriate letters if they are ever typed by mistake. Copying the characters from one project into another can easily introduce invalid characters, if you do not verify what characters the new project actually uses.
Designating Alphabetic Order for a Language
The order of the characters in the Alphabetic Characters dialogue determines how words are sorted in the Paratext project. There are many places where Paratext needs to present information as a sorted list, using the “alphabetic” order you define here. Some of these places would be:
- Search results in a list window
- The Wordlist tool
- Glossary (if a project has one)
💡 If Paratext is not sorting things as you expect, one of the reasons could be the order of the characters in the Alphabetic Characters dialogue.
Accented Characters
It is common for languages to have accented characters, such as á ê ɨ ñ ò ü. These should be included in the Alphabetic Characters list for a project. Consider the vowels in the Spanish example below:

Notice that the lower and upper case of each accented character is included. Also notice that the accented vowels are on the same line as the unaccented ones. This is not required but is an option that is used when you want Paratext to ignore the accents when sorting. This can be helpful if your language has something like tonal/stress markings that don’t change the meaning of the word.
If the sort order were configured like the above example, Paratext would NOT treat e and é as different letters when sorting. For example, the following hypothetical words would be sorted this way:
- pepa
- pépa
- pepas
- pépas
Sorting this way will also prevent your glossary from having separate sections for words that start with different accented characters.
Sorting Accented Characters Independently of the Non-Accented Ones
If you want the accented characters to be sorted independently of the non-accented ones (for example: treat them as different letters), then the accented characters need to be placed on separate lines. Consider the modified Spanish example below:

If the sort order were configured like the above “modified Spanish” example, the following hypothetical words would be sorted this way (because e comes before é):
- pepa
- pepas
- pépa
- pépas
It seems to be more common to configure a project so that accented and unaccented vowels sort together, while accented and unaccented consonants are sorted independently of each other. Consider the example of ñ/Ñ from the Spanish example below:

This configuration will cause Paratext to sort normal n’s separately from ñ’s with the tilde diacritic. The following hypothetical words would be sorted this way, because n comes before ñ:
- sonir
- soñir
- sunara
- suñara
It will also cause the glossary to have two separate sections, for words beginning with “N” and “Ñ“, if you chose to have a glossary in your project.
Digraphs
Digraphs, trigraphs and other multi-graphs are used in many writing systems. You have the ability to tell Paratext how to sort these. Some language communities give a lot of attention to multi-graphs because they are very important to the spelling in their language, while others are content to have Paratext ignore them and only sort based on the individual characters. Let’s consider a middle-ground case in the Fulfulde example below that has four digraphs (mb, nd, ng, and nj):

In this example, Paratext will distinguish between words starting with these digraphs and words starting with a single-character, and will sort them accordingly. For example:
- maayii
- mbaajii
- nanii
- ndaranii
- ngaari
Characters that May Need a Special Keyboard
There are many characters that your project may need but your computer cannot type without adding a keyboard solution that includes those special character(s). Examples of these characters are ç /Ç, ɨ/Ɨ , Ŋ/ŋ, ɓ/Ɓ, ɔ/Ɔ and many others. The Fufulde has hooked b (ɓ) and hooked d (ɗ) and are examples of this. You will need a way to either type these characters, or a way to copy and paste them into the Alphabetic Characters list. One way to be able to type special characters is using the Autocorrect feature in Paratext. For more details on Autocorrect see this article:
A second way is to find or install a Keyman keyboard. This is the best solution if your project needs many special characters, and/or if you want to type special characters in other programs on your computer. Many Keyman keyboards also have special keyboards for typing on mobile devices (for example: Android or iOS phones).
Avoid Using Punctuation as an Alphabetic Character
It is very important to keep punctuation characters separate from word-forming (alphabetic) characters. Failing to do so can cause all kinds of problems. Searches and sorts will not work correctly; the character, punctuation and spelling checks may not find all the errors; and the Wordlist tool may break words in unexpected places.
Example: Some Latin-based writing systems use a little tick mark to represent a glottal stop, and people often will type an apostrophe ‘ or right single quotation mark ‘ for that tick mark. Similarly, some orthographies represent the velar n (ŋ) with ng’ using either the apostrophe or right single quotation mark. However, neither of these two symbols is normally a word-forming character and the computer may not process them the way you expect (that is, it will treat them as punctuation instead of a letter). One limitation of using these is that they have now lower and upper case. Instead, it is recommended to use either the Latin Small letter Saltilloꞌ (U+A78C) or the Modifier letter apostrophe ʼ (U+02BC) since the computer will recognize them as word-forming characters and not punctuation. Normally, orthographies do not need an upper case for the glottal stop, but if you do, then use the the Latin Small Letter Saltillo ꞌ (U+A78C) and the Latin Capital Letter Saltillo (U+A78B). As with the other special characters, you will need a way to type the character you choose for the glottal stop.
Consider the example below that is using the Saltillo to represent the glottal stop:
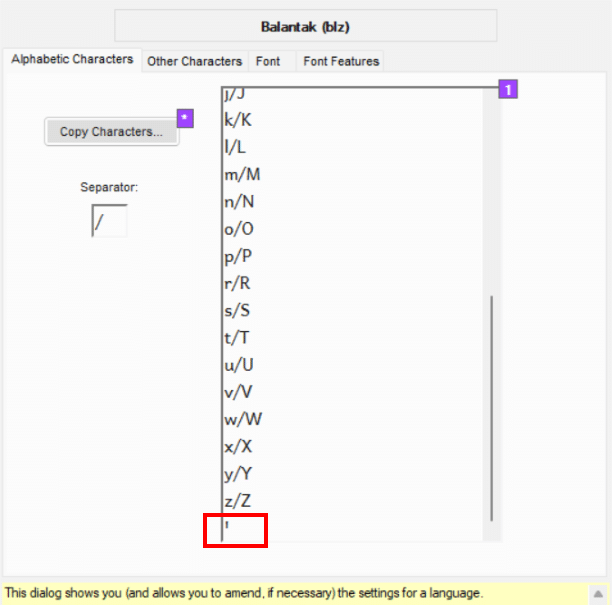
💡 Notice that characters like the Saltillo often represent the glottal stop or are part of a trigraph like ngꞌ that do not need an upper-case form in the orthography. If an orthography requires and upper-case Saltillo, then place the Latin Capital Letter Saltillo (U+A78B) after a forward slash like this: ꞌ/Ꞌ.
Contractions and Hyphenation
Many languages use contractions. For example, English has words like “don’t”, “doesn’t” and “won’t”. It is common for orthographies to mark vowel elision with apostrophes such as “mʼchikhulupiriro mwa Khristu Yesu” (Chichewa/Nyanja). So, apostrophes are needed for correct spelling, but they are not considered letters or word-forming characters. The same can be said about hyphens: some orthographies need them for proper spelling but are not considered word-forming.
The way to handle contractions and hyphenation in Paratext is to specify them as word-medial punctuation. The Word-medial punctuation setting is found on the Other Characters tab, under Language Settings. Consider the Word-medial punctuation setting for Nyanja shown below:
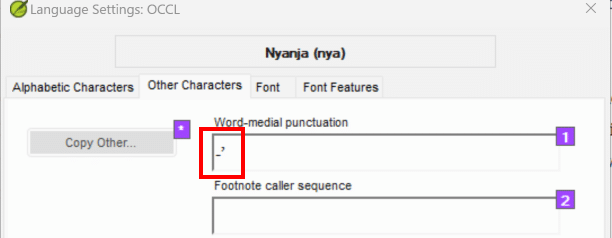
Placing the hyphen and the apostrophe here tells Paratext that some words will have hyphens or apostrophes. This is important because if the hyphen and apostrophe are not listed here, then Paratext will divide all words with hyphens or apostrophes into two parts. For instance, the Nyanja word mʼchikhulupiriro would be broken into two words (m chikhulupiriro) where the apostrophe occurs. Similarly, the Fulfulde word adotoo-mi would be broken into two words (adotoo mi) where the hyphen occurs.
Conclusion
In review, the Alphabetic Characters list should have all the word-forming characters needed for your language. Unused characters should not be left there. (This often happens when the Alphabetic Characters list from one project is copied to another.) Punctuation should never be used as part of an alphabet. If the need for this arises, then find another acceptable-looking character to represent that letter in Paratext. You may need to find or create a method to type special characters not produced by your computer’s keyboard. The Autocorrect feature in Paratext or Keyman are two good possible solutions.
Taking the time at the beginning of a translation project to properly sort out the alphabetic characters of your project will make the job of drafting and checking the translation much easier. It will also make typing the text less of a chore, and it will allow many of Paratext’s searching, sorting, and checking functions to work properly.