

Paratext Now Gives Users Control over Normalization
A recent update has added a new normalization setting.
We are recommending that users review this setting and determine if a change should be made for their projects.
The majority of projects migrated from Paratext 7 will have normalization set to “Off”. This might not be the best setting for your project. The rest of this article describes in very brief form what Unicode normalization is, and the meaning of the three available settings for it. It will be up to you to determine what the best setting for your project.
Brief description of Unicode Normalization
Unicode normalization is the process of establishing the rules for how characters that can be represented in more than one way under the Unicode standard should be represented in a given project. Lack of consistency in how these characters are represent in a Paratext project leads to problems with searches and filters not working as expected, and can cause poor looking publications.
For those not so familiar with Unicode issues, I think an example will help. The letter “e” with an acute accent, “é” can be generated by the computer using one Unicode point (U+00E9), or with the normal “e” (U+0065) plus the acute accent (U+0301). The problem is when there is a mixture of these two representations in the same Paratext project. To humans all the “é” are the same, but to Paratext they are different. Therefore if one searches for the code point (U+00E9), the search will not find any of the words where “é” has been represented by the normal “e” (U+0065) plus the acute accent (U+0301). The first representation is known as “composed” since the two parts of the character are joined or composed into a single character. The second representation is known as “decomposed”, since it is split into two parts or decomposed.
Normalization Control added to Project Properties and Settings
The Project Properties settings dialogue now has a normalization select box. (Line 4 in the screen capture shown here.) The user could not control how normalization was done in earlier versions of Paratext 8.
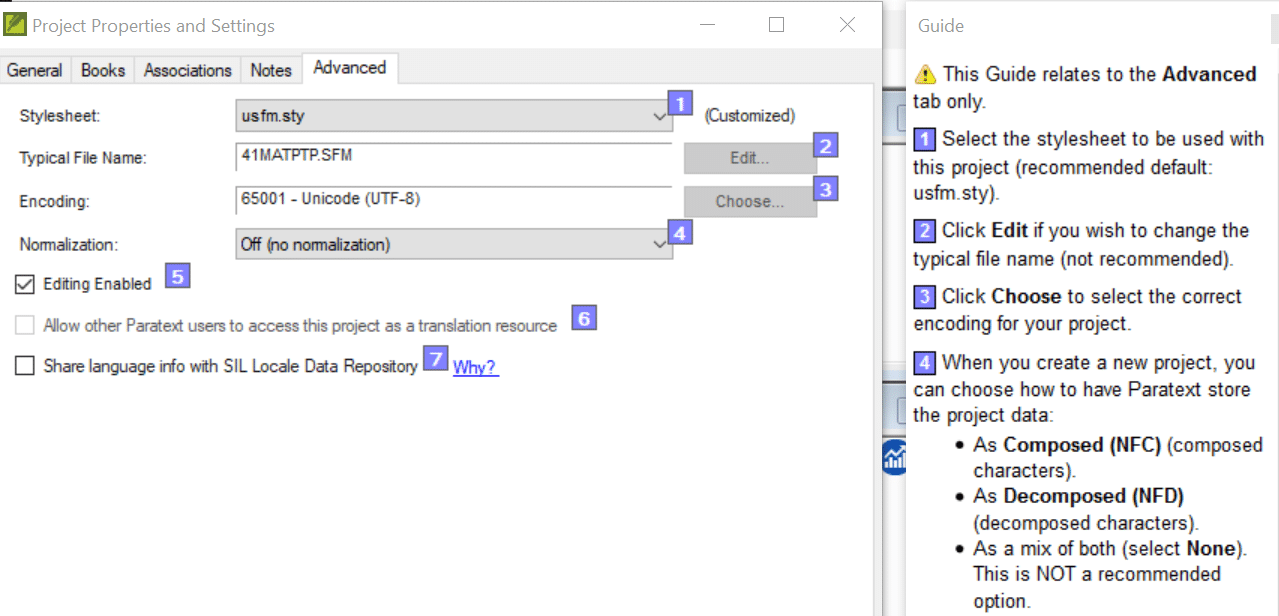
Normalization Feature
The normalization feature has three choices: 1) Off (no normalization), 2) Composed characters (NFC), and 3) Decomposed characters (NFD).

Normalization: Off
The default choice for projects migrated from Paratext 7 is “Off”. When this is selected, Paratext will not attempt to change the character codes in anyway. It will accept whatever is typed in even if some computers on a team are using composed characters (NFC) and others are using decomposed (NFD).
Normalization: Composed
Selecting “Composed” will tell Paratext that whenever a character is typed in as decomposed (NFD) it should change it to composed when possible. Characters that do not have a composed form available will of course be left as decomposed. If it should happen that a decomposed character is entered, Paratext will change it to its composed form the next time the project is saved. Characters will be consistent in the sense that every specific character will only have one form in the project.
Normalization: Decomposed
Selecting “Decomposed” will tell Paratext that whenever a character is typed in as composed (NFC) it should change it to decomposed if a decomposed representation exists. If it should happen that a composed character is entered where a decomposed form exists, Paratext will change it to its decomposed form the next time the project is saved. Characters will be consistent in the sense that any character that could be represented by a decomposed form will be.
Normalization Defaults
The default normalization setting for new projects is “Composed”. Since this is a new feature, it is recommended that you consider if your project needs normalization or not and if so which kind would be appropriate.
The default normalization setting for existing projects is “Off”. When the feature was added to Paratext 8, the upgrade did not attempt to automatically set normalization. Nor did it prompt you to make a choice. If you use accented characters or have a custom keyboard, then it is recommended that you take the time to set the normalization in a fashion appropriate for your language.
Which Normalization Should I Use?
It is beyond the scope of this article to give all reasons about whether to use composed or decomposed characters. Your organization should provide guidance on this issue. If you would like to see an example of thinking through these issues, you can go to the following link and read about the decision that was made about encoding in Cameroon:
https://langtechcameroon.info/composed-characters/
The important thing from a Paratext perspective is to be consistent and always represent a character the same way. Software uses the underlying codes and not the appearance of characters when doing its work.
Conclusion
Maintaining consistent representation of characters will ensure that searches in Paratext will find all the relevant words. Specifying the appropriate normalization for your project can also avoid some formatting problems that can occur during publishing.
Specifying a normalization for a project has the added benefit that the differences between the keyboards in a team are less important. One computer can be using composed characters, while another uses decomposed and Paratext will automatically make the data consistent for you.